
All of this series is mainly based on the Machine Learning course given by Andrew Ng, which is hosted on cousera.org.
Gradient Descent with Large Datasets
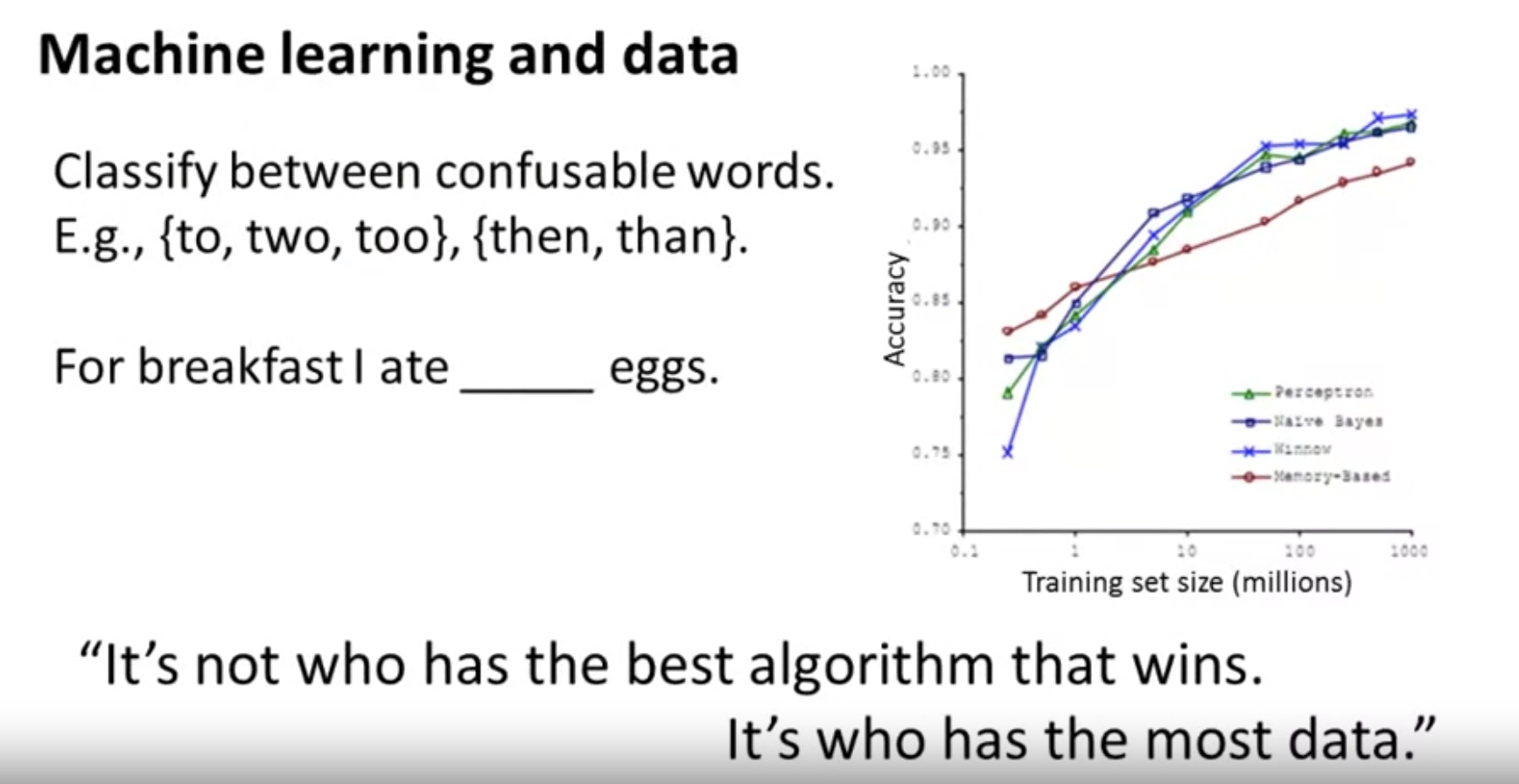
Large training set size causes both $J_{train}$ and $J_{CV}$ to be high with $J_{train}≈J_{CV}$.
If a learning algorithm is suffering from high bias, getting more training data will not (by itself) help much
Experiencing high variance:
Low training set size: Jtrain(Θ) will be low and JCV(Θ) will be high.
Large training set size: Jtrain(Θ) increases with training set size and JCV(Θ) continues to decrease without leveling off. Also, Jtrain(Θ) < JCV(Θ) but the difference between them remains significant.
If a learning algorithm is suffering from high variance, getting more training data is likely to
Stochastic Gradient Descent
When we have a very large training set, gradient descent becomes a computationally very expensive procedure. In this video, we’ll talk about a modification to the basic gradient descent algorithm called Stochastic gradient descent

Batch Gradient Descent:
\[J_{\text {train}}(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}\]Repeat: \(\begin{aligned} \theta_{j}:=\theta_{j} &-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} \\ & \text { (for every }j=0, \ldots, n) \end{aligned} (for every \(j=0, \ldots, n)\)
Stochastic Gradient Descent:
\[\begin{array}{l}{\text { 1. Randomly shuffle (reorder)}} {\text { training examples }} \\ {\text { 2. Repeat }\{} \\ {\qquad \begin{aligned} \text{for }i:=1,...m\{\\ \theta_{j}:=& \theta_{j}-\alpha\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} \\ & \quad \quad(\text { for every } j=0, \ldots, n) \\\} \end{aligned}} \\ ~~~~~~~~~~~~~~~~\} \end{array}\]Note: Repeat the loop 1~10 times.
Mini-Batch Gradient Descent
use b examples in each iteration: b normally lies in [2,100]
Algorithm: Say b=10, m=1000
\[\begin{array}{l}{\text { Repeat }\{} \\ {\text { for } i=1,11,21,31, \ldots, 991 \{} \\ {\qquad \theta_{j}:=\theta_{j}-\alpha \frac{1}{10} \sum_{k=i}^{i+9}\left(h_{\theta}\left(x^{(k)}\right)-y^{(k)}\right) x_{j}^{(k)}} \\ { \text { (for every }j=0, \ldots, n)} \\ {\mathrm{~ \} ~}}\end{array} \\ \}\]Advantage of Mini-Batch GD: Since we add over b examples, vectorization can be used. Good solvers can partially parallelize the computation over the b examples.
Stochastic Gradient Descent Convergence
Checking for convergence:


Since the stochastic gradient descent method can oscillate around the optimum solution, the convergence is not guaranteed.
One possible solution is to update the learning rate $\alpha$: $\alpha =\frac{C_1}{\text{Iteration Number}+C_2}$
where the $C_1$ and $C_2$ are two fixed parameters, which need to be calibrated.
Advanced Topics with large scale problem
Online Learning
The online learning setting allows us to model problems where we have a continuous flood or a continuous stream of data coming in and we would like an algorithm to learn from that.
Note:
- There is no fixed training set. Even though the algorithm is similar to the stochastic optimization algorithm, it is different in terms of the existence of a fixed training set.
- Due to the lack of fixed training set, online learning algorithm can adapt to changing user preference.
- If the data volume is moderate, we can apply the fixed training set algorithm.
Example 1:

Example 2:

Map Reduction and Data Parallelism
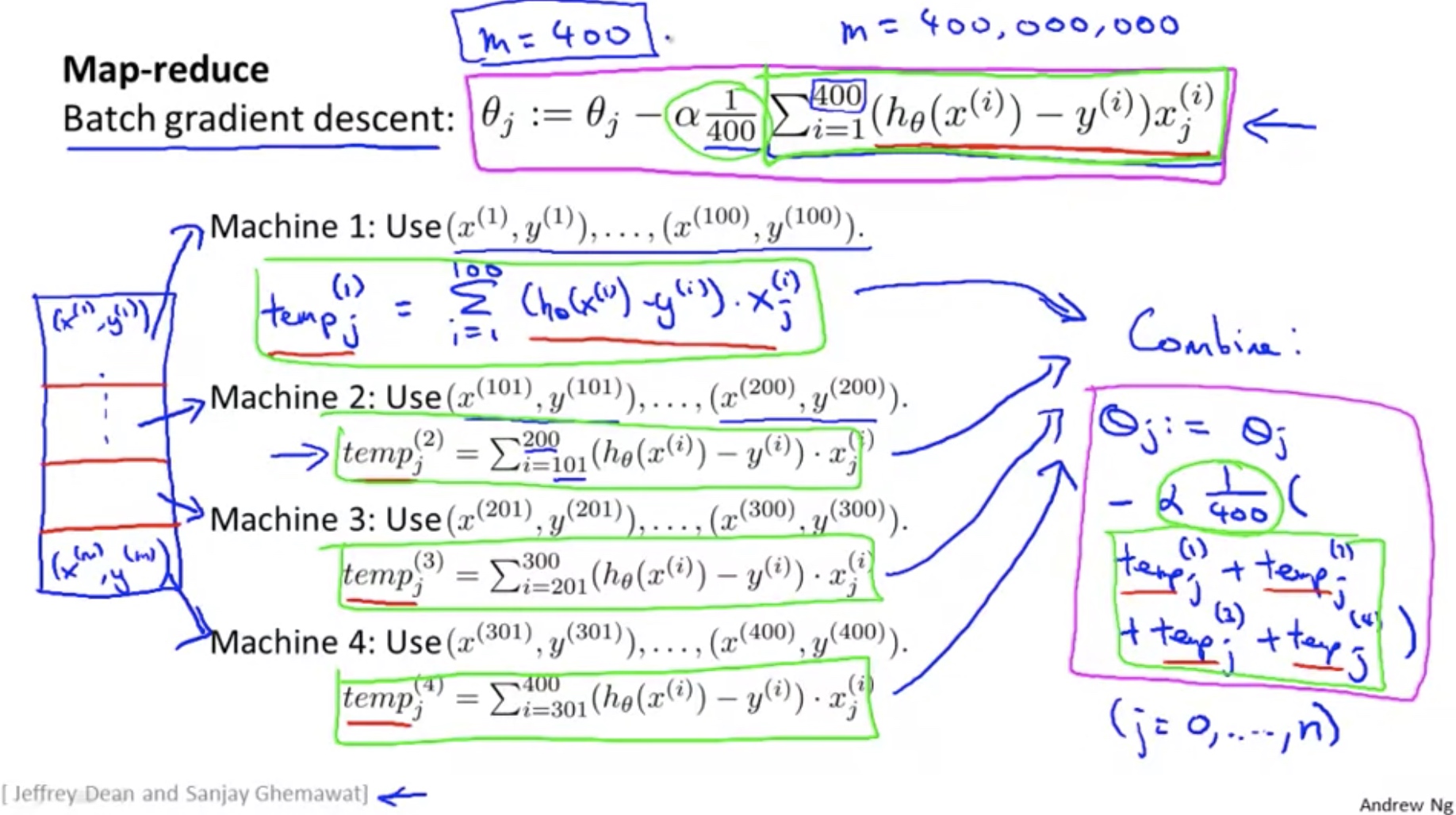

Note:
- Many learning algorithm can be expressed as computing sums of functions over the training set.
- May be subject to network latency

Note:
- some linear algebra library automatically takes advantage of parallel computation. In this case, as long as the algorithm is expressed in a well vectorized fashion, there is no need to apply this multi-core or map reduction manually.
Application: Photo OCR
Problem Description and Pipeline
Photo OCR stands for Photo Optical Character Recognition.
Photo OCR Pipeline:
- Text Detection
- Character Segmentation
- Character classification
- Correct(optional)

Pipeline breaks down the OCR problem into a sequence of tasks and modules.
Sliding Windows
The aspect ratio is relatively fixed.
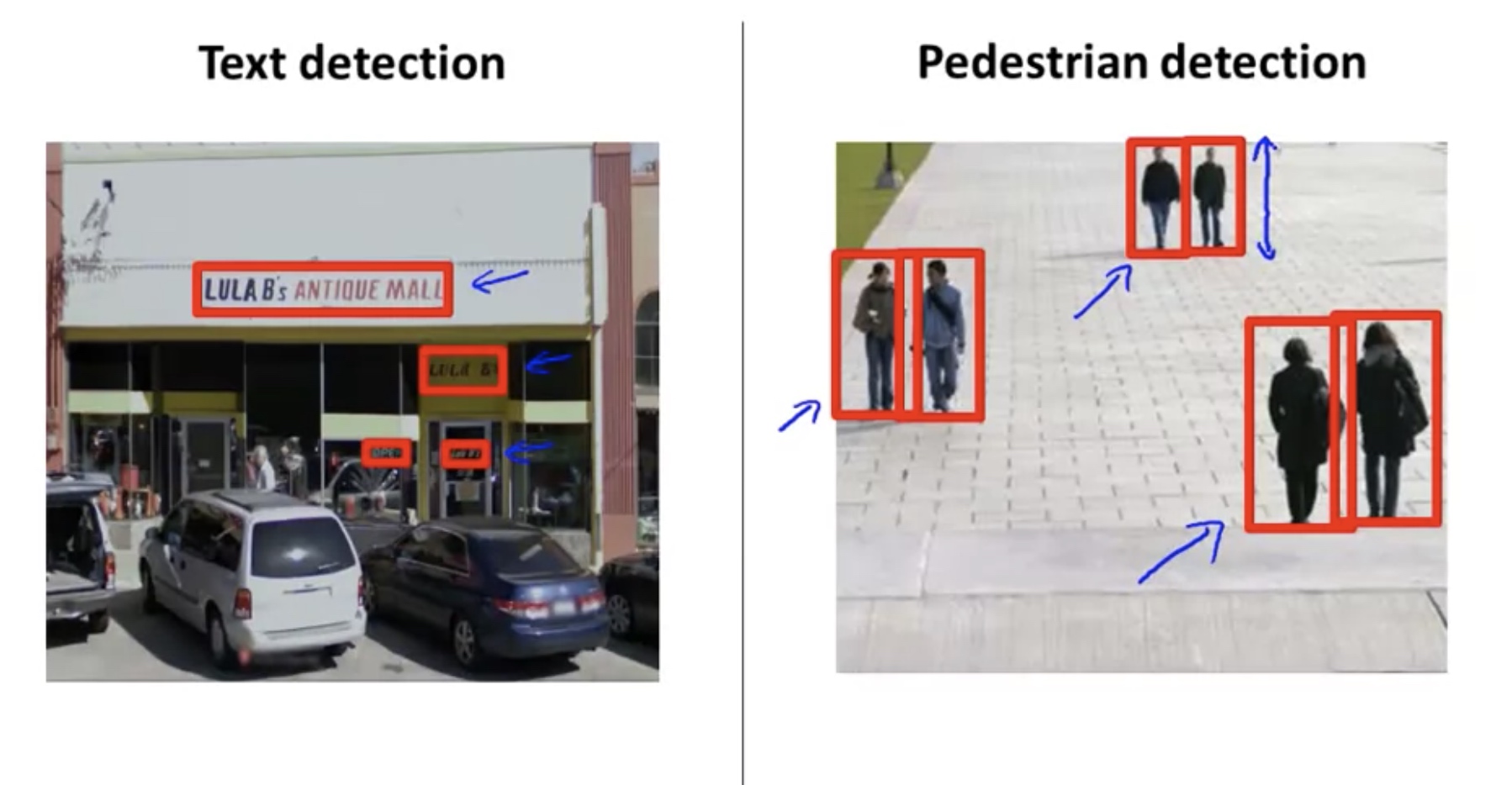
Supervised learning for pedestrian detection:

Sliding window detection
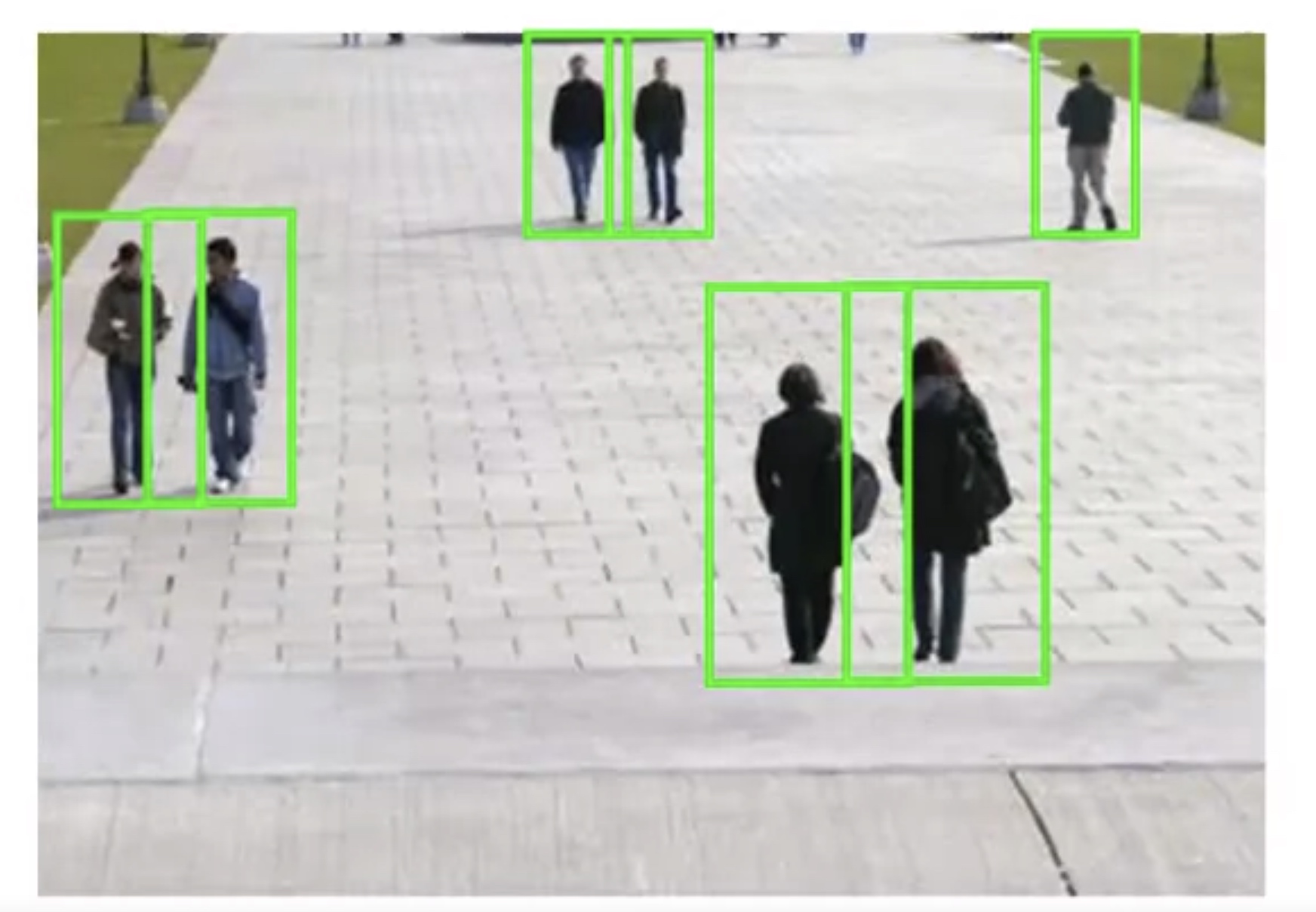
Iterate on (size of the rectangular, position of the rectangular). For text detection:

Character segmentation:

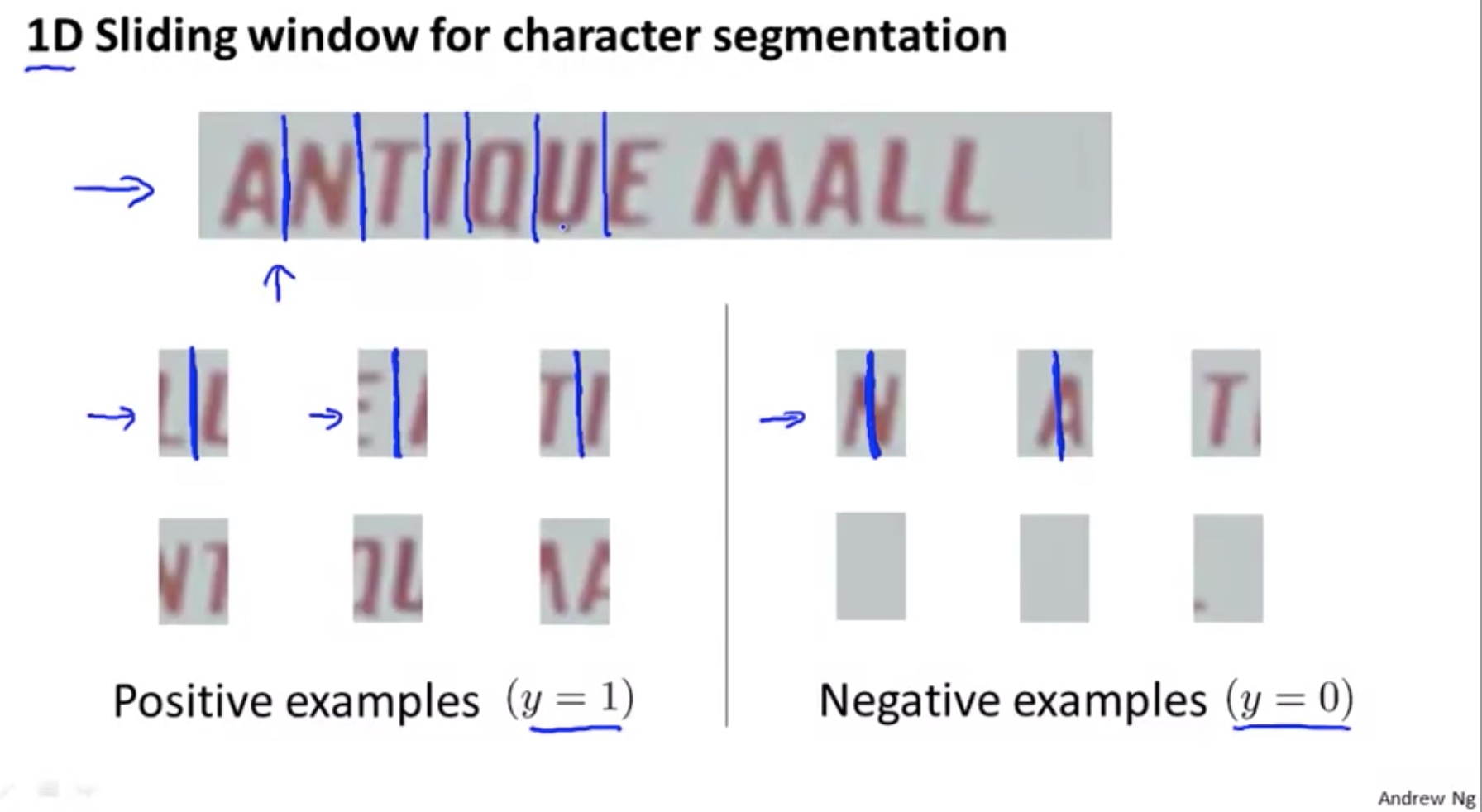
Getting lots of data and artificial data
It has been seen over and over that one of the most reliable ways to get a high performance machine learning system is to take a low bias learning algorithm and to train it on a massive training set.
But where did you get so much training data from? Turns out that the machine earnings there’s a fascinating idea called artificial data synthesis, this doesn’t apply to every single problem, and to apply to a specific problem, often takes some thought and innovation and insight. But if this idea applies to your machine learning problem, it can sometimes be a an easy way to get a huge training set to give to your learning algorithm. The idea of artificial data synthesis comprises of two variations, main the first is if we are essentially creating data from [xx], creating new data from scratch. And the second is if we already have a small label training set and we somehow have amplify that training set or use a small training set to turn that into a larger training set and in this video we’ll go over both those ideas.
Possible ways of creating meaningful artificial data:
- add affine transformation, rotations
- different fonts
- change the color or use grey photo directly
- add distortions and blurring operators
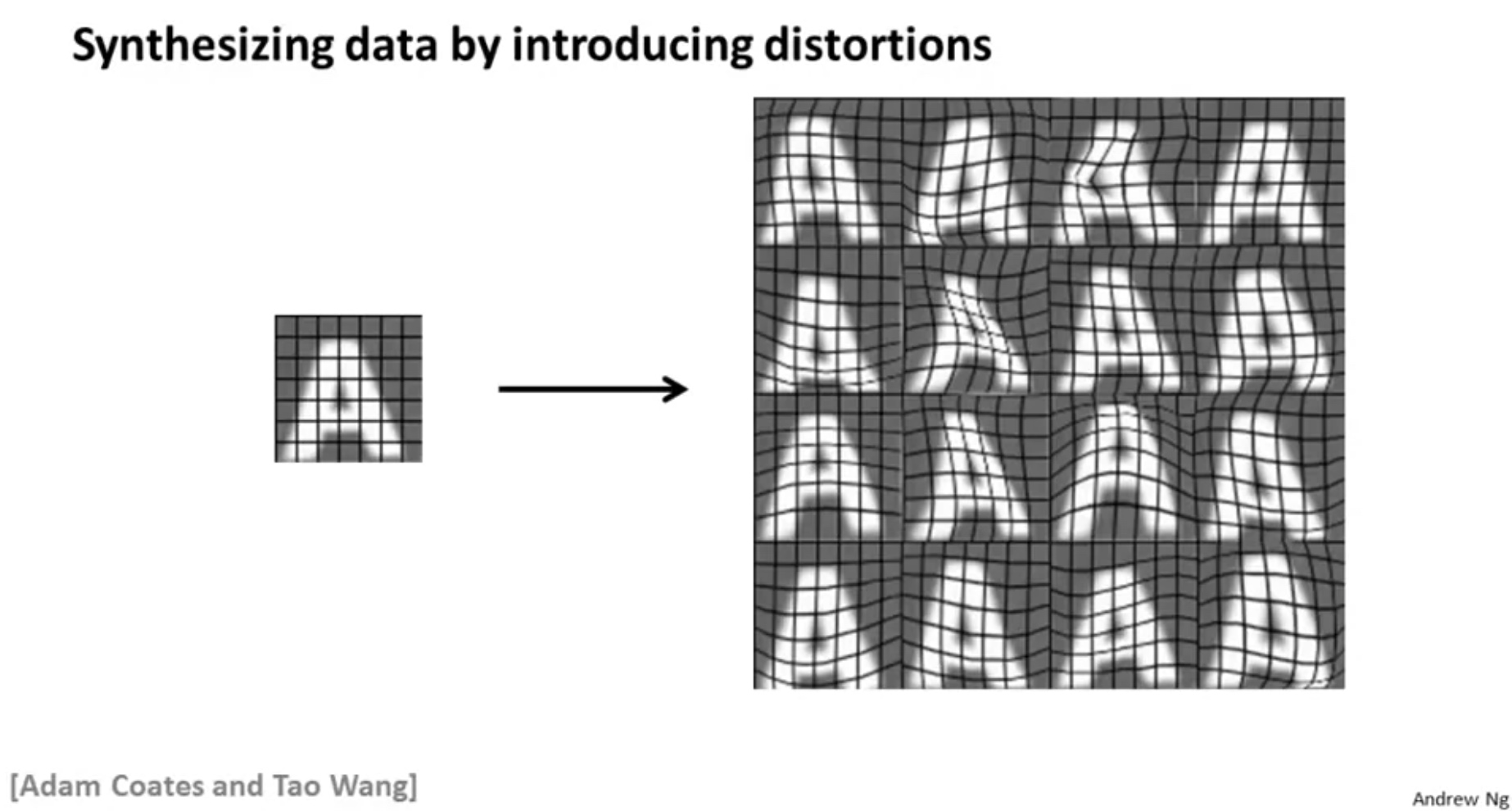

Notes:
- Before spending efforts on adding examples, make sure the bias $J_{\text{test}}$ is small. If not, add features/hidden layers.
- How much work would it cost to get 10X data
- Artificial data synthesis: generating data from scratch or add distortion to existing data.
- Collect/label it mannually
- Crowd sourced data labeling.
For example, if we have limited number of data, then label 10X more data is practical. However, if the current m is large, it is more applicable to using artificial data synthesis to get 10X data.
Ceiling Analysis: what part of the pipeline to work on next

Overall Accuracy = f( Accuracy in Step 1,…, Accuracy in Step m)
Say $Acc_i:=\text{accuracy in step i}$
Ceiling analysis is a optimization problem: $\max_{Acc} f(Acc)$
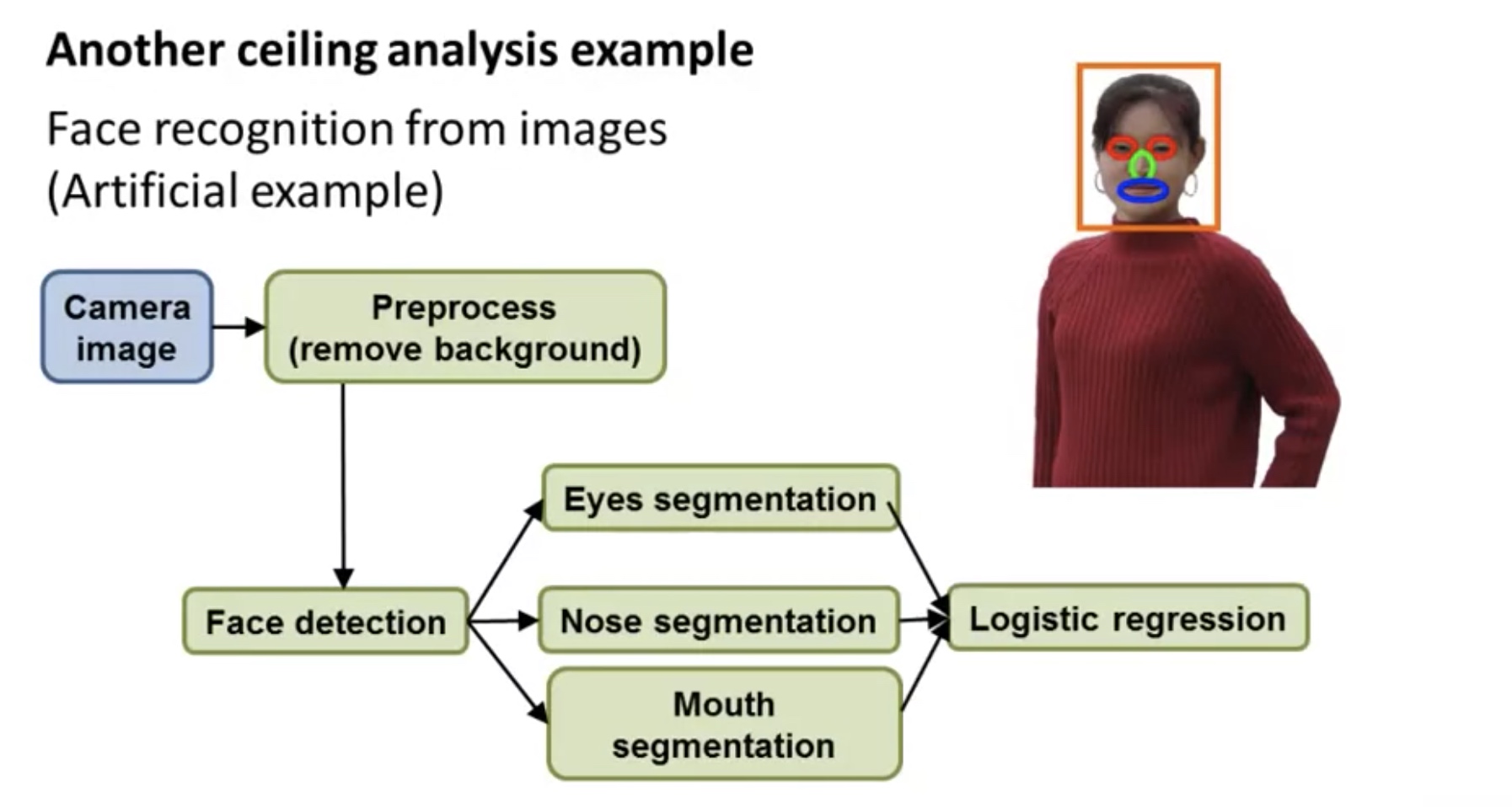
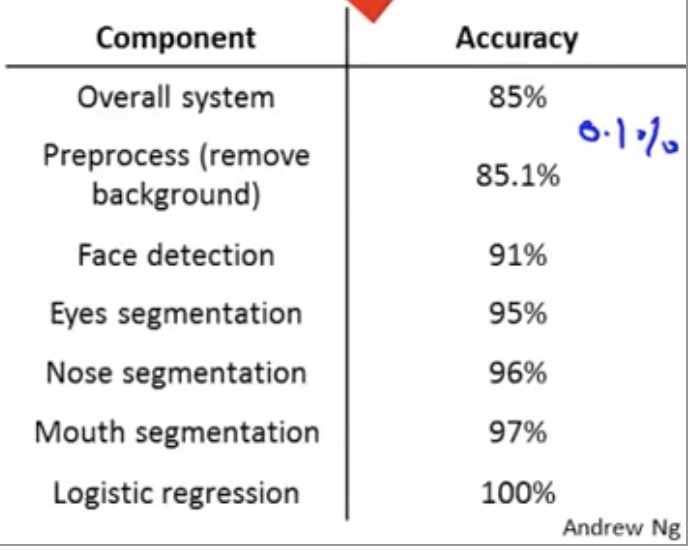
The accuracy for step i means the overall accuracy if all the steps j ($j\leq i$) is 100% accurate.
It is better to work on face detection process, which can improve the accuracy by 6%.
In contrary, it is less rewarding to work on background remove process, which only improves the overall accuracy by 0.1%.
Ng: And in this video we’ll talk about this idea of ceiling analysis, which I’ve often found to be a very good tool for identifying the component of a video as you put focus on that component and make a big difference. Will actually have a huge effect on the overall performance of your final system. So over the years working machine learning, I’ve actually learned to not trust my own gut feeling about what components to work on. So very often, I’ve work on machine learning for a long time, but often I look at a machine learning problem, and I may have some gut feeling about oh, let’s jump on that component and just spend all the time on that. But over the years, I’ve come to even trust my own gut feelings and learn not to trust gut feelings that much. And instead, if you have a sort of machine learning problem where it’s possible to structure things and do a ceiling analysis, often there’s a much better and much more reliable way for deciding where to put a focused effort, to really improve the performance of some component. And be kind of reassured that, when you do that, it won’t actually have a huge effect on the final performance of the overall system.
Summary: main topics
- Supervised Learning
- Linear regression, logistic regression, neural networks, SVMs
- Unsupervised Learning
- K-means, PCA, Anomaly Detection
- Special applications/topics
- recommendations system (collaborative filtering), large scale machine learning
- Advice on building a machine learning system
- bias/variance, regularization; deciding what to do on next; evaluation of learning algorithm, learning curves, error analysis, ceiling analysis
Comments